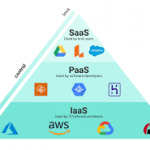
Le Cloud Computing

Mais où va l’Informatique: le Cloud Computing Pour comprendre l’avenir de l’informatique, il faut d’abord comprendre quels produits et technologies occuperont le devant de la scène dans les années à venir. Bien que rien ne soit jamais sûr, l’examen des tendances actuelles et des projections peut aider à anticiper l’évolution de l’informatique. Pour beaucoup de travailleurs de l’information, l’une des plus grandes répercussions peut venir des appareils qu’ils utilisent pour réaliser leur travail. La fin des années 2000 a été…